Saturday, September 8, 2012
The Time2 Library and CrNiCKL now in Maven Central
Thursday, September 6, 2012
Is it broke? Can we fix it?
Experts met on January 19, 2012 at the International Telecommunication Union to decide whether to abolish leap seconds. Due to a lack of consensus among participants it was decided to postpone the decision (BBC News). It was a classical standoff between those who want sharp, systematic solutions and the advocates of
if it ain't broke, don't fix it.A few months later, on June 30, 2012, yet another leap second was added, causing problems at some websites. Wired reported it under the dramatic sounding heading
The Inside Story of the Extra Second That Crashed the Web. The discussion is open: is it broke? Can we fix it?
Wednesday, August 29, 2012
The Time2 Library and CrNiCKL support Maven
The software is not yet available from The Central Repository,
but can be found in a freely accessible maven repository on GitHub.
To use it, specify this in your POM or settings:
Links:
<repository>
<id>jpvetterli on github.com</id>
<url>https://raw.github.com/jpvetterli/maven-repo/master/releases/</url>
</repository>
Time2 Library project
CrNiCKL database project
Tuesday, July 17, 2012
CrNiCKL 1.1.0 released with all delete methods renamed
delete in the CrNiCKL software.
This was a bad idea because such methods are useless when called from JavaScript.
Indeed, delete is a reserved word in js.
All such methods have been renamed and
a new version of the software has been released to the
project website,
to SourceForge and the GitHub repositories. The following scheme
has been used for renaming. Parameterless delete methods are now
named destroy. The others are now typically named deleteFoo
where Foo is the type of (one of) the parameter(s).
I decided to completely eliminate the old methods rather than let them live a bit longer as deprecated. I did it because the software is not yet used out there. In case I misread the stats, please accept my apologies. In any case the previous version remains available on all the websites mentioned.
Friday, July 13, 2012
Source code sharing
Although the source of the projects I discuss in this blog was already available for downloading via the project websites, it can now be browsed more comfortably at GitHub.
The relevant repositories are:
- time2lib
- for the Time2 Library
- crnickl
- for the CrNiCKL base system
- crnickl-jdbc
- for the JDBC support of CrNiCKL
- crnickl-demo
- for the CrNiCKL demos
The game of the name
Chronicles are the most important objects in the ChronoDB CrNiCKL database. So I started from them to find a new name. I settled on CrNiCKL because it can be pronounced like "chronicle" and there are practically no hits for it in Google. I also decided to write the name with most of the letters in uppercase, so it stands out in text.
The software remains available under its old name, for a while at least, but won't be updated. Blog posts related to ChronoDB will not be updated but will get a notice about the rename.
The new project website is http://agent.ch/timeseries/crnickl/.
Wednesday, July 11, 2012
Time2 Library project home page updated
quote of the day:
Wow.
If you need speed, compactness, and flexibility, then the Time2 Library is
for you. There is no trade off. Even with the wildest time domains
(calendars if you prefer) a time point is just a number.
In many cases it is even less than that: it is an array index.
The flexibility comes into play only if and when needed,
for example when printing or scanning a date.
Monday, July 9, 2012
ChronoDB and geographical coordinates
Important notice. On July 13, 2012, the ChronoDB project was renamed CrNiCKL, which is pronounced like "chronicle". All packages, demos included, have been renamed. The new project website is at http://agent.ch/timeseries/crnickl/. The old project remains accessible for a while at http://agent.ch/timeseries/chronodb/. The remainder of this article remains valid mutatis mutandis.
I've just released another ChronoDB demo to show how to set up a
database with time series of geographical coordinates.
The demo can be found in the package ch.agent.chronodb.demo.geocoord
in archive chronodb-demo-1.1.0.jar
at the ChronoDB project website or on SourceForge.
GeoCoord is a toy Java interface for geographical coordinates, with three methods:
GeoCodeValueScanner and a less simple implementation of
ValueAccessMethods<GeoCoord> named
AccessMethodsForGeoCoord. The Database class itself is so
small it can be listed completely here:
To make things interesting the demo uses a special time domain, with time points at 7:00 AM, 9:00 AM, 3:11 PM, and 9:33:20 PM every Monday, Tuesday, Friday, and Saturday. For a refresher on time domains, please have a look at my previous post.
Here is what running the demo looks like (commands are on a single line and
output has been truncated):
Friday, July 6, 2012
Time Series Framework Design
With time playing a rather important role in this world, sequences of things ordered by time are present in many kinds of systems. Because the idea of time is intuitively familiar, it is tempting to choose a simplistic design when modeling a system or even not to think about it at all. Ironically, simplistic designs can lead to needlessly complex implementations, as annoying issues are addressed one after the other.
Stated informally, a time series is a set of elements uniquely identified by a discrete point in time or by a time interval. The Time Series Framework requires a more precise definition:
A time series is characterized by a value type and a time domain. All elements of a time series have a value of the same type, the value type, or can be recognized as missing. Any element can be uniquely identified by a point in the time domain of the series.Note that the definition does not explicitly allow for time ranges identifying values. This is generally not a problem because of the nature of time domains.
The terms used in the definition will be explained shortly, but before that a few typical problems will be discussed. These problems should illustrate why a framework for time series is useful.
Problems and design goals
Let us look at a series alternating between two constant values every working day: Friday=5, Monday=10, Tuesday=5, Wednesday=10, Thursday=5, Friday=10, Monday=5, Tuesday=10, and so on. The series has never any data on weekends. Consider this straightforward chart plotting the values on the vertical axis against their dates, on the horizontal axis:
 |

|
Tel Aviv, Cairo, New York
Beyond this contrived example, there are many situations with no data on weekends. A familiar case is provided by stock markets. These are also a good illustration of the annoying details hiding in seemingly simple problems: weekends are not the same in Tel Aviv, Cairo, and New York. When designing a database for global stock market data, or when drawing charts to compare the prices of some American, Egyptian, or Israeli stocks, such issues must be dealt with.
Getting a good grip on the time domain is the first important design goal of the Time Series Framework.
Missing values
The following table lists the first eleven Olympic Games.
| 1896 | Athens |
| 1900 | Paris |
| 1904 | Saint-Louis |
| 1908 | London |
| 1912 | Stockholm |
| 1916 | |
| 1920 | Antwerp |
| 1924 | Paris |
| 1928 | Amsterdam |
| 1932 | Los Angeles |
| 1936 | Berlin |
Eleven? It is true that there are ten Games, but it is also true that the list has eleven elements. Is something wrong here? No. Games had been scheduled in Berlin in 1916 but were canceled because of the war. Conceptually, the Games of 1916 are a missing value, and there are many real world phenomena modeled with time series where it is common to have some values missing. A system dealing with time series must be capable of dealing with such cases gracefully and in a useful way. You don't want your software to return the nine first Games when you asked for ten, or to crash on the Games of 1916. Or you don't want your portfolio evaluation software to give up when a quote is missing. And as a software developer, you don't want to invent ad-hoc solutions all the time.
Detecting missing values and handling them intelligently is the second important design goal of the Time Series Framework.
The pieces of the puzzle
Time domain
Time index
A time index is in a time domain and carries a discrete offset which defines a point in time. Two time indexes in the same time domain can be compared, with a larger index corresponding to a later point in time. Adjacent points in time are represented by adjacent offsets.
Because time indexes are expected to be used as keys it is important to implement them as immutable objects.
Time range
A time range is a pair of time indexes in the same time domain, called the lower and upper bound. If the lower bound is larger than the upper bound the range is said to be empty.
Observation, value type, missing value
An observation has a time index and a value of some type. The value type must allow the definition of a special value representing missing values, without restricting the set of useful values; null (nil) can only be used as this special value if it has no other meaning in the relevant context.
Time series
A time series maps a set of time indexes to values. All time indexes are in the same time domain and all values are of the same type. For this reason we talk of the time domain and the value type of a time series.
A time series can be defined alternatively as a set of observations, with each element of the set uniquely identified by its time index.
A time series has a range defined by the smallest and largest time indexes of the included observations.
A time series maintains the abstraction of missing values, which correspond to time indexes in the range for which no observation exist. This definition implies that a time series can never have missing values at its boundaries. This is also true for a subset of a time series, because it is also a time series.
Time series storage
Although an implementation detail, the storage of time series presents an interesting design question. That a series maps time indexes to values does not mean that it has to be stored in a dictionary keyed by time indexes. The Flyweight pattern provides a better solution, making use of the fact that for a given time domain, time indexes can be represented by integer values, the offsets.Two cases must be considered, depending on the frequency of missing values. In a regular time series, missing values are exceptional. In a sparse time series, they are the rule.
Sparse series are useful for managing irregular events. They are typically implemented as dictionaries. Missing values are not stored. Instead of time indexes, only offsets are used as keys. The time domain is stored only once. Time indexes are reconstructed if and when needed.
The storage of regular series is straightforward and efficient. All values, missing or not, are stored into an array. With missing values the exception, the overhead is reasonable, and because they are self-signaling, missing values are always detectable. In addition to the array, the series stores also the time domain and the offset of the time index of the value in the first array element. A time index can be reconstructed from the time domain and the sum of the stored offset and the array index of the value.
Time Series Framework Design
by Jean-Paul Vetterli is licensed under a Creative Commons Attribution 3.0 Unported License.

Walking through the ChronoDB demo (2/2)
Important notice. On July 13, 2012, the ChronoDB project was renamed CrNiCKL, which is pronounced like "chronicle". All packages, demos included, have been renamed. The new project website is at http://agent.ch/timeseries/crnickl/. The old project remains accessible for a while at http://agent.ch/timeseries/chronodb/. The remainder of this article remains valid mutatis mutandis.
This post is the second of a two-part commentary on the ChronoDB demo. In the first part I explained the steps for setting up a ChronoDB database before it can be used to perform useful work.
Setting up the schema for the demo happens on the last line of our code snippet:
db appears in this post, it stands for the ChronoDB database.
StocksAndForexSchema constructor:
ValueScanner. But the constructor is not finished with its work. It needs to tell ChronoDB that we are going to have numeric series:
applyUpdates() seen here and there consolidates all pending modifications to an object but does not commit them to permanent storage.
When the constructor is done, things get more specific, as can be seen from the code of createSchema:
We want to represent a stock using a chronicle with two attributes, ticker, and currency, and with three series, price, volume, and splits. Price and volume have a custom series attribute, unit. The first thing to do is to create a schema.
The demo does not use the possibility to inherit from another schema.
The last step in setting up the schema is to create top level chronicles. The demo uses two collections: stocks and exchange rates. The code below shows how to create the top chronicle hosting the exchange rate collection.
With top-level chronicles created, the demo can go ahead.
Once the required schemas have been set up, application rarely, if ever, need to do anything about them. Millions of chronicles can be created, and their attributes and series are automatically available without dong anything, except setting specific values.
In many cases it is not even necessary to set values of attributes. Take the case of american stocks. It is a simple matter to define a schema for them, inheriting from
the "Stocks" schema we made in the demo:
As a final remark, it is important to note that as the default value of a chronicle attribute can always be overriden (it's named a default value after all), the value of a series attribute cannot. It keeps its default value, as defined in the schema. If you say in the schema that the unit of a series foo is bar then in all collections having this schema, the foo series unit will be bar. The same goes for built-in attributes: name, type, time domain, and sparsity of a series cannot be changed once defined. This does not restrict the modeling freedom. As the demo as shown you can have price series in different currencies. The price and volume have a unit ("in currency", and "in number of shares"), but the price series unit "in currency" simply tells to look at the chronicle's currency. So you will have your Toyotas in quoted in yens and your Renaults in euros.
Thursday, July 5, 2012
Walking through the ChronoDB demo (1/2)
Important notice. On July 13, 2012, the ChronoDB project was renamed CrNiCKL, which is pronounced like "chronicle". All packages, demos included, have been renamed. The new project website is at http://agent.ch/timeseries/crnickl/. The old project remains accessible for a while at http://agent.ch/timeseries/chronodb/. The remainder of this article remains valid mutatis mutandis.
A demo package is available for downloading from the ChronoDB project website or from SourceForge. In a short series of posts I will comment on a few important details. I hope these explanations will be helpful.
Explanations will focus on the following code snippet from the static main method of StocksAndForexDemo:
The constructor invocation new StocksAndForexDemo(args[0])
initializes a ChronoDB database, kept in a private member inside the demo:
ch.agent.chronodb.api.SimpleDatabaseManager, which is one of the few non-interface classes in that package. It is provided to make it easier to write test cases (and demos). It sets up the database using parameters provided in a file on the file system or the class path. Here is an extract from such a file:
SimpleDatabaseManager currently supports only one database. Parameters beginning with "session." are specific to the JDBC implementation. Implementations more sophisticated than JDBCDatabase used in this simple demo will have more parameters, some of which are named in the interface ch.agent.chronodb.impl.DatabaseBackend.
At this point, a ChronoDB database object and a JDBC connection are ready for use but there is absolutely nothing in the database yet. In fact, the demo uses an in-memory HyperSQL database. Before the demo starts and after the demo terminates, the database does not exist. So the next step is to create the tables and indexes expected by the JDBC implementation of ChronoDB.
This is done by the method invocation demo.setUpHyperSQLDatabase() which sends SQL data definition language (DDL) statements to the database engine for execution. The DDL is taken from Resources/HyperSQL_DDL_base.sql. This file is in
chronodb-jdbc-1.0.0.jar and therefore on the class path. The DDL defines all tables required by the base system, with various indexes and constraints to enforce referential integrity. Browse the SQL file if you need details. Noteworthy are the few non DDL statements at the end of the file, which initialize the database with the built-in properties needed when defining a series in a schema. These properties require in turn the corresponding built-in value types.
These value types are:
- name, a string type enforcing a minimalist naming policy
- type, for values defining the type of a series
- timedomain, a restricted type for time domains, with some predefined values: daily, datetime, monthly, workweek, and yearly
- binary, a boolean type
- Symbol (name)
- Type (type)
- Calendar (timedomain)
- Sparsity (binary)
At this point the database is ready for useful work directly related to the problem at hand: setting up the schema for the demo. This will be the subject of a forthcoming post.
Wednesday, June 27, 2012
The ChronoDB database for time series released
Wednesday, March 21, 2012
Maintenance release of the Time2 Library
This maintenance release is plug-compatible with the previous version of the software. The internal management of diagnostic messages and exceptions has been improved in three ways:
- Diagnostic messages are fetched and formatted only when actually needed. This improves performance, especially in the case where not all messages are logged by the application environment.
- The library has now its own exception type, T2Exception. Because it is a subclass of the exception type used previously there is no compatibility issue.
- Messages are now keyed symbolically instead of literally. This provides many benefits to the programmer. One of these is readily visible in the Eclipse IDE where the text of the diagnostic message is displayed as a tooltip when the mouse pointer idles over a message key. The screenshot below shows this in action.
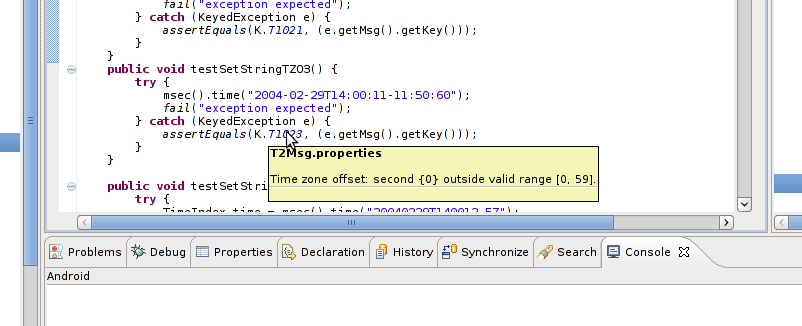
As an aside, the snapshot shows a piece of JUnit testing code. Writing software is easier and faster with test-first development. JUnit is a simple and powerful testing pattern for Java. We can thank Beck and Gamma for it. Note that the original idea was developed for Smalltalk by Kent Beck in 1989 and thus predates Java.
Coming soon
A data management system for time series running on top of the Time2 Library is in the pipeline. I hope to release it one of these weeks...